The most technologically astute businesses, militaries, and policy makers have begun to make use of a new kind of digital twin to support their decision making – one which, beyond merely reflecting the current state of its physical twin in visualised data, is also able to use that data to run simulations and make predictions on likely developments and outcomes in the physical twin’s runtime. Predictive digital twins present a powerful tool to decision makers for avoiding failure, maximising efficiency, and achieving best possible outcomes in the management of highly sensitive and complex physical systems.
Of course, the utility of predictive digital twins only goes so far as the likelihood of their predictions being correct, and this is largely predicated on simulations being able to use accurate real-world data as a jump-off point. The process of calibrating a digital twin according to complex real-world data, continually synchronising in line with evolving real-world circumstances, and running multiple simulations at speed for optimal predictive accuracy requires not only the right calibration methods but also, crucially, enough computing power to do it in an operationally viable timeframe. This is where many organisations encounter a barrier to implementing predictive digital twins, and where we at Hadean have been working to offer a tailor-made solution.
In this blog, we’re going to discuss how Hadean has been working with Imperial College and Oxford University to accelerate modelling of the COVID-19 pandemic, covering the following points:
- The challenges of creating and calibrating a digital twin, given the complexity of its physical counterpart (in this case, human society in the midst of a pandemic)
- An explanation of Approximate Bayesian Computation (ABC) methods, and why we’ve chosen them as the basis for our digital twin calibration
- The importance of continuous synchronisation for avoiding nonsense predictions, as shown in our data
- Hadean’s work in making this possible, and how this applies to broader digital twin use cases
The modelling of an ongoing pandemic is hard. One of the main reasons for this difficulty is that the properties of a pandemic are continuously changing, and so we are at risk of our models becoming out of date before we ever have a chance to use them. We’ve seen people’s behaviours change as social distancing and mask-wearing have come and gone, we’ve seen people’s immunity change as vaccines have been rolled out, and we’ve even seen the virus itself change, as new variants with new properties have emerged. Since the goal of modelling is ultimately to aid in decision making for pandemic response, capturing these changes in our modelling is vital. What works for Alpha may not work for Delta, and what is totally necessary when there is no immunity in the population might be unnecessarily restrictive with enough vaccination. If our models do not reflect the present reality we may get our response disastrously wrong.During the pandemic, Hadean’s Innovation team has been working closely with academic partners at Imperial College and Oxford University to accelerate pandemic modelling using Hadean technology. During this time, the problem of keeping models synchronised with reality as the pandemic evolves has been one of our primary focuses. Here we will show how Hadean technology can enable the calibration of an agent-based COVID-19 predictive digital twin model and the recalibration of the same model during the emergence of a novel variant.
Calibrating and Recalibrating for a new variant (Problem, Solution & Results)
Our work on modelling the pandemic involves the use of complex, agent-based models such as OpenABM-Covid19 (https://github.com/BDI-pathogens/OpenABM-Covid19) developed at Oxford University. This model simulates each member of a population as an individual agent, interacting with other agents at home, in the workplace and elsewhere in order to simulate how a virus spreads through the population. This is a very powerful tool for understanding how the situation will develop further and provides a test-bed for understanding the effect of interventions such as lockdowns. However, such a complex model naturally requires a lot of information to be provided as parameters. To give just a few examples –
- What is the probability of infection when an infected and uninfected person interact?
- What proportion of the population have some immunity?
- How strong is that immunity?
- What proportion of cases are asymptomatic?
To be confident in the results of our model, we need to be confident in our estimation of these parameters.
Thankfully, because of the daily testing results released by governments, and the efforts of large scale testing projects such as ZOE and React we have access to a large amount of data to help us find values for these parameters. What we need is a principled method to use data we currently have access to about the spread of the virus to estimate the value of these parameters so that our model can extrapolate into the future.
Approximate Bayesian Computation for Digital Twin Calibration
The gold-standard for calibration of agent-based models is a class of methods known as Approximate Bayesian Computation (ABC). ABC methods have two key advantages. They do not require models to meet any special conditions and can be applied to any model, regardless of its complexity. Additionally they do not just give a point estimate of the value of a parameter, they instead give a probability distribution over all possible parameters, this gives us a measure of how confident we can be in the calibration.
ABC methods are based on a simple assumption, the closer the parameterization is to being correct, the closer the output of the model will be to real data. An ABC method will intelligently generate candidate sets of parameters, carry out simulations using these parameters and measure the distance between the output of those simulations and what was observed in the real world. The results of these evaluations are then used to estimate the likelihood that certain sets of parameters are correct, and fed back into the ABC algorithm to drive the selection of further candidates. As more samples are generated ABC methods are guaranteed to converge towards the best possible (Bayesian) estimate of the parameter values given the available data.
In order to get good results from ABC we need to evaluate a large number of samples. Here, the Hadean platform allows us to go beyond what would otherwise have been possible in a feasible timespan. The covid simulations that follow take 6 minutes on a modestly populated network. To run all the simulations required to find the parameter distribution we converge upon took 6 iterations of 128 samples, a total of 768 independent simulation runs. If run sequentially, this would have taken 77 hours. With a suitably high-spec laptop you might be able to run up to 4 of these simulations in parallel given their heavy workload – taking you to 20 Hrs. Using the Hadean platform we can instead spawn as many workers as desired horizontally. Using 32 workers we were able to achieve the full ABC calibration in 2 hours, compared to the expected 77 you might achieve on your laptop – 97% faster.
With the Hadean platform as an accessible tool for mathematical modellers the scaling of processes is put in their hands. Rather than require involved DevOps systems and transfer friction, the end-user is able to scale their simulations in order to drive decision making at pace.
Initial Model Calibration Against Real-World Data
OpenABM-Covid19 is an open-source agent-based covid19 simulation developed by epidemiologists at Oxford University. The simulator has been used in prior academic studies, including to explore the efficacy of contact-tracing apps. Hadean has been integrating a separate spatial epidemiology project in order to tie together detailed covid simulation with high fidelity geospatial networks. This produces a highly complex model. In order to produce insights, particular care must be taken to calibrate so that results well-match data observed in the real world in both time and geography.
In a previous blog post (https://hadean.com/accelerating-pandemic-decision-support-with-the-hadean-platform/) we go into more detail about these models, show how we used Hadean Technology to scale a simulation to use millions of agents and how we worked together with our academic partners to investigate the utility of different interventions in combatting the pandemic.
The first step we undertake is ensuring that the underlying strain that circulates in the OpenABM-Covid19 model behaves as observed in a time of low transmission, r_0=1, where, on average, for each individual infected only one more individual becomes infected. This is because we are interested in modelling the virus mid-pandemic – when there is both immunity and disease already present in the population.
Starting with a naïve population, with no infection, one must first introduce an underlying amount of infection. For epidemiological studies it is important that this infection is age-stratified – that the right proportion of infection is given to the right age groups. Consider the difference between instances where only the vulnerable elderly are infected versus only the young. Another difficulty pertinent in the epidemiology space is the observability model. The actual number of infections in a population is impossible to measure (not least due to asymptomatic infection and imperfect test accuracy). Instead, the number of people infected must be predicted from the number of cases observed. To address this we introduce a seeding algorithm that works over a seeding period. In this seeding period the population is ‘forced’ through age-proportioned artificial infections that intend to match the true data, using an algorithm we developed at Hadean for the purpose. For a period of a month the simulation is ‘pumped’ so that the state of the simulation at the end models the state of the world from the data.
After the seeding period the simulation is continued uninterrupted. We calculate a distance between the real data and the simulated data in the region simulated beyond the seeding period. This distance can be fed into ABC as a measure of the goodness-of-fit of the parameters being evaluated.
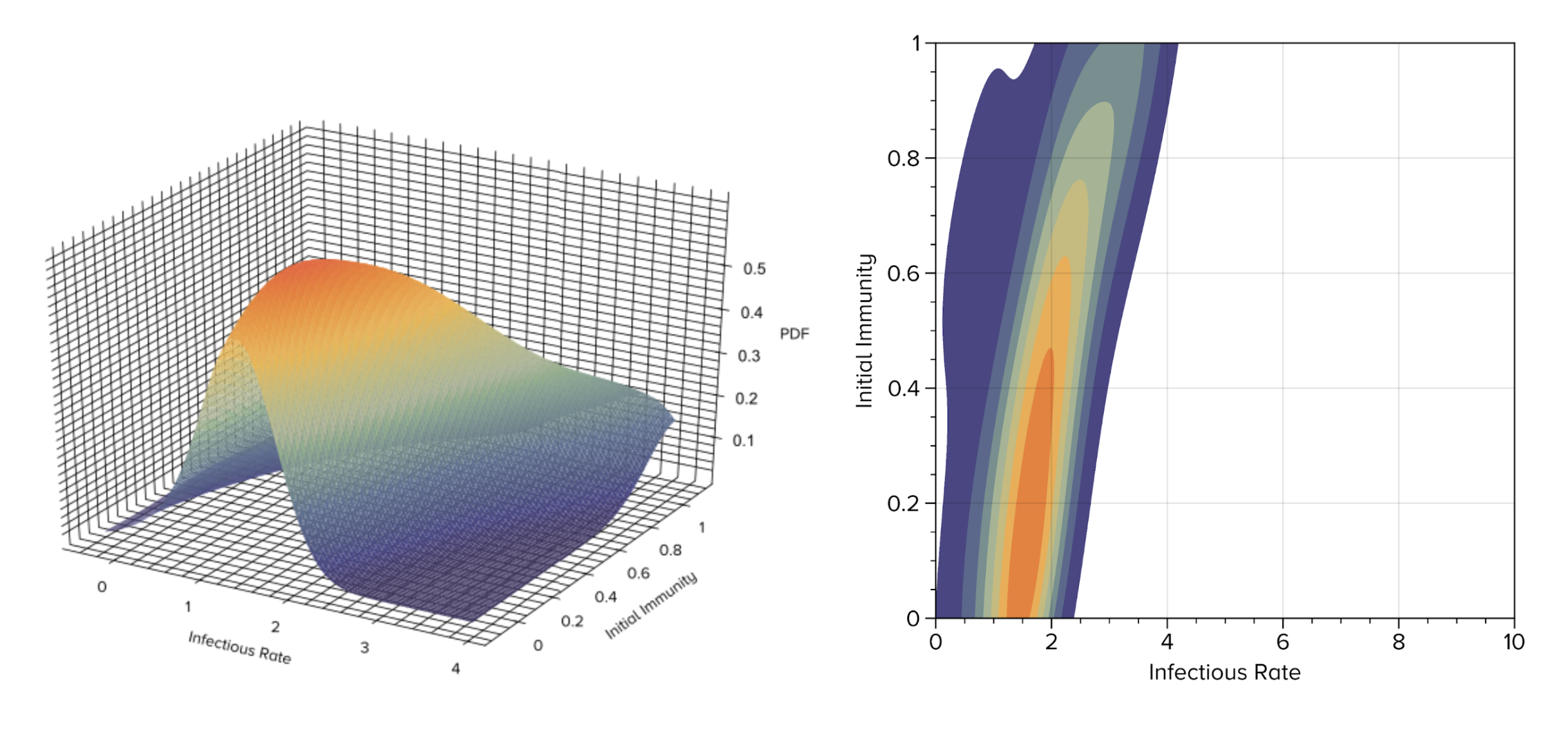
Using ABC parameters for the infectious rate of the base virus and initial immunity of the population are found. Figure 1 visualises the output from ABC: the distributions of likely parameters that best match the covid cases from data during the time period being simulated. See that the darkest orange region is considered optimal – that relatively low initial immunity, and pretty small infectious rate for the simulator matches real data. It is important to note that we do not find a single optimal point, rather we find a region of best parameters. We can see that there might well be some relationship that can be drawn to match the true data that balances infectious rate and initial immunity.
Using a single parameter tuple from the dark orange region we can re-simulate and see the full output of the calibrated model. In the animated GIF below, Figure 2, we see that the simulation initially follows close to the true data cases line. The calibrated model initially proves useful, as the predicted number of cases is close to the true number of cases. This gives us a model which predicts reality well… until, of course, the world changes.
Model Synchronisation when the World Changes
When covid mutates and a new strain is introduced our simulation needs recalibrating, or synchronising, with the real-world data. Models can fall out of calibration, slowly over-time or through substantial bifurcations in reality and in the idealised model. We find our model deviates significantly beyond timestep 60 – shown in Figure 2. With exterior subject-matter knowledge we know that this maps well to the introduction of a new strain, the delta-variant, which became prevalent at the time of the G7 summit. Hadean’s work in this space is more generally looking at the impact of the G7 summit on covid spread.

The model is therefore updated. We expect that this surge of cases is caused by an influx of a new strain in the population that coincides with the G7 summit in Cornwall. To model this, OpenABM-Covid19 allows distinct strains. We find ourselves in a similar position to which we started. The new strain must be calibrated so that it is capable of providing reasonable future insights.
Figure 3 details the experiments on one plot. The first ABC experiment discussed, for the Figure 1, uses a seeding period between the first two blue dashed lines, A-B, and with the distance metric that compares true data to simulated in the region between B and C. The second ABC experiment to parameterise a new variant uses as static parameters the values from the first ABC experiment, seeding at the start, running the model freely in the same region, then at step 58, C, introducing a new virus with variable initial immunity and viral strength to be calibrated over. The distance metric for the second experiment is how well the model matches the true data beyond the line D.
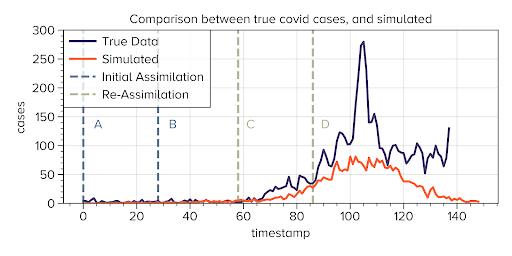
In particular, Figure 3 utilises the best output from both ABC experiments, and the orange line can be seen as the best way to match the true data using parameters in the OpenABM-Covid19 simulation. What is of note is the ability for the simulation to match the peak of the new strain influx. Most importantly, note the stark difference in our recalibrated model in Figure 3 versus the initial model previously plotted in Figure 2. Model recalibration is a necessity in maintaining predictive digital twins for policy planning.
Beyond the pandemic – real-time data assimilation for digital twins
We will end here with a quick summary of what this work with Imperial College and Oxford University has taught us, and how Hadean’s technology was crucial to its execution.
In epidemiological modelling, it was found that predictive digital twins, once calibrated, require continuous resynchronisation with real-world data in order to provide decision makers with reliable modelling. We were therefore tasked with leveraging Hadean technology to keep a complex epidemiology model calibrated in the introduction of a new strain, finding Approximate Bayesian Computation to be a suitable method for doing so, both due to its model agnosticity, and because the confidence estimates it provides in a distribution of parameters gives a deeper understanding of the complex model than other techniques. Our success in this regard has established a foundation for investigating the effect of large-scale introductions of new variants in the future.
Beyond pandemic modelling, this work has taught us a lot about the importance of model calibration to the decision support process in general. We can distil this down into two core learnings:
1. Your model is only useful when you can be confident it correctly reflects reality
2. A model which is correct at one point in time can be dangerously wrong at another without recalibration
Digital twins as found in industry and defence are also susceptible to desynchronisation and must be recalibrated to provide operational utility. Without the ability to calibrate and synchronise complex digital twins with variable real-world data in a timely and accurate manner, simulation insights are incapable of providing suitable staging for developing real-world policy or systems control. For example, the following Digital Twins would be of limited use:
– A digital twin of disease spread, where you haven’t parameterised the immunity to the virus
– A digital twin of a jet engine, where you haven’t found the correct value of the friction and wear on the bearings
– A digital twin of a supply chain, where you don’t know how the network responds to bad weather
Hadean’s cloud-enabled calibration enables decision makers to leverage dynamically provisioned computing resources in the cloud, ensuring access to the computing power required to deliver predictive simulation data that is comprehensive, accurate and timely enough to provide confidence in decision-making and guide teams through uncertainty at pace.
Aside from impacting pandemic response, examples of how Hadean technology has benefited decision makers include enabling a multinational pharmaceutical company to support decision making across its global supply chain, as well as serving as the technological backbone for ‘The Forge’, a Digital Decision Support Engine for military operations developed by Cervus. In each case, the Hadean platform has proven to be an essential component in revolutionising operational efficiency in complex and highly time-sensitive contexts.
If you’d like to know more about Hadean’s capabilities with Digital Twins, please continue reading here.
The most technologically astute businesses, militaries, and policy makers have begun to make use of a new kind of digital twin to support their decision making – one which, beyond merely reflecting the current state of its physical twin in visualised data, is also able to use that data to run simulations and make predictions on likely developments and outcomes in the physical twin’s runtime. Predictive digital twins present a powerful tool to decision makers for avoiding failure, maximising efficiency, and achieving best possible outcomes in the management of highly sensitive and complex physical systems.
Of course, the utility of predictive digital twins only goes so far as the likelihood of their predictions being correct, and this is largely predicated on simulations being able to use accurate real-world data as a jump-off point. The process of calibrating a digital twin according to complex real-world data, continually synchronising in line with evolving real-world circumstances, and running multiple simulations at speed for optimal predictive accuracy requires not only the right calibration methods but also, crucially, enough computing power to do it in an operationally viable timeframe. This is where many organisations encounter a barrier to implementing predictive digital twins, and where we at Hadean have been working to offer a tailor-made solution.
In this blog, we’re going to discuss how Hadean has been working with Imperial College and Oxford University to accelerate modelling of the COVID-19 pandemic, covering the following points:
- The challenges of creating and calibrating a digital twin, given the complexity of its physical counterpart (in this case, human society in the midst of a pandemic)
- An explanation of Approximate Bayesian Computation (ABC) methods, and why we’ve chosen them as the basis for our digital twin calibration
- The importance of continuous synchronisation for avoiding nonsense predictions, as shown in our data
- Hadean’s work in making this possible, and how this applies to broader digital twin use cases
The modelling of an ongoing pandemic is hard. One of the main reasons for this difficulty is that the properties of a pandemic are continuously changing, and so we are at risk of our models becoming out of date before we ever have a chance to use them. We’ve seen people’s behaviours change as social distancing and mask-wearing have come and gone, we’ve seen people’s immunity change as vaccines have been rolled out, and we’ve even seen the virus itself change, as new variants with new properties have emerged. Since the goal of modelling is ultimately to aid in decision making for pandemic response, capturing these changes in our modelling is vital. What works for Alpha may not work for Delta, and what is totally necessary when there is no immunity in the population might be unnecessarily restrictive with enough vaccination. If our models do not reflect the present reality we may get our response disastrously wrong.During the pandemic, Hadean’s Innovation team has been working closely with academic partners at Imperial College and Oxford University to accelerate pandemic modelling using Hadean technology. During this time, the problem of keeping models synchronised with reality as the pandemic evolves has been one of our primary focuses. Here we will show how Hadean technology can enable the calibration of an agent-based COVID-19 predictive digital twin model and the recalibration of the same model during the emergence of a novel variant.
Calibrating and Recalibrating for a new variant (Problem, Solution & Results)
Our work on modelling the pandemic involves the use of complex, agent-based models such as OpenABM-Covid19 (https://github.com/BDI-pathogens/OpenABM-Covid19) developed at Oxford University. This model simulates each member of a population as an individual agent, interacting with other agents at home, in the workplace and elsewhere in order to simulate how a virus spreads through the population. This is a very powerful tool for understanding how the situation will develop further and provides a test-bed for understanding the effect of interventions such as lockdowns. However, such a complex model naturally requires a lot of information to be provided as parameters. To give just a few examples –
- What is the probability of infection when an infected and uninfected person interact?
- What proportion of the population have some immunity?
- How strong is that immunity?
- What proportion of cases are asymptomatic?
To be confident in the results of our model, we need to be confident in our estimation of these parameters.
Thankfully, because of the daily testing results released by governments, and the efforts of large scale testing projects such as ZOE and React we have access to a large amount of data to help us find values for these parameters. What we need is a principled method to use data we currently have access to about the spread of the virus to estimate the value of these parameters so that our model can extrapolate into the future.
Approximate Bayesian Computation for Digital Twin Calibration
The gold-standard for calibration of agent-based models is a class of methods known as Approximate Bayesian Computation (ABC). ABC methods have two key advantages. They do not require models to meet any special conditions and can be applied to any model, regardless of its complexity. Additionally they do not just give a point estimate of the value of a parameter, they instead give a probability distribution over all possible parameters, this gives us a measure of how confident we can be in the calibration.
ABC methods are based on a simple assumption, the closer the parameterization is to being correct, the closer the output of the model will be to real data. An ABC method will intelligently generate candidate sets of parameters, carry out simulations using these parameters and measure the distance between the output of those simulations and what was observed in the real world. The results of these evaluations are then used to estimate the likelihood that certain sets of parameters are correct, and fed back into the ABC algorithm to drive the selection of further candidates. As more samples are generated ABC methods are guaranteed to converge towards the best possible (Bayesian) estimate of the parameter values given the available data.
In order to get good results from ABC we need to evaluate a large number of samples. Here, the Hadean platform allows us to go beyond what would otherwise have been possible in a feasible timespan. The covid simulations that follow take 6 minutes on a modestly populated network. To run all the simulations required to find the parameter distribution we converge upon took 6 iterations of 128 samples, a total of 768 independent simulation runs. If run sequentially, this would have taken 77 hours. With a suitably high-spec laptop you might be able to run up to 4 of these simulations in parallel given their heavy workload – taking you to 20 Hrs. Using the Hadean platform we can instead spawn as many workers as desired horizontally. Using 32 workers we were able to achieve the full ABC calibration in 2 hours, compared to the expected 77 you might achieve on your laptop – 97% faster.
With the Hadean platform as an accessible tool for mathematical modellers the scaling of processes is put in their hands. Rather than require involved DevOps systems and transfer friction, the end-user is able to scale their simulations in order to drive decision making at pace.
Initial Model Calibration Against Real-World Data
OpenABM-Covid19 is an open-source agent-based covid19 simulation developed by epidemiologists at Oxford University. The simulator has been used in prior academic studies, including to explore the efficacy of contact-tracing apps. Hadean has been integrating a separate spatial epidemiology project in order to tie together detailed covid simulation with high fidelity geospatial networks. This produces a highly complex model. In order to produce insights, particular care must be taken to calibrate so that results well-match data observed in the real world in both time and geography.
In a previous blog post (https://hadean.com/accelerating-pandemic-decision-support-with-the-hadean-platform/) we go into more detail about these models, show how we used Hadean Technology to scale a simulation to use millions of agents and how we worked together with our academic partners to investigate the utility of different interventions in combatting the pandemic.
The first step we undertake is ensuring that the underlying strain that circulates in the OpenABM-Covid19 model behaves as observed in a time of low transmission, r_0=1, where, on average, for each individual infected only one more individual becomes infected. This is because we are interested in modelling the virus mid-pandemic – when there is both immunity and disease already present in the population.
Starting with a naïve population, with no infection, one must first introduce an underlying amount of infection. For epidemiological studies it is important that this infection is age-stratified – that the right proportion of infection is given to the right age groups. Consider the difference between instances where only the vulnerable elderly are infected versus only the young. Another difficulty pertinent in the epidemiology space is the observability model. The actual number of infections in a population is impossible to measure (not least due to asymptomatic infection and imperfect test accuracy). Instead, the number of people infected must be predicted from the number of cases observed. To address this we introduce a seeding algorithm that works over a seeding period. In this seeding period the population is ‘forced’ through age-proportioned artificial infections that intend to match the true data, using an algorithm we developed at Hadean for the purpose. For a period of a month the simulation is ‘pumped’ so that the state of the simulation at the end models the state of the world from the data.
After the seeding period the simulation is continued uninterrupted. We calculate a distance between the real data and the simulated data in the region simulated beyond the seeding period. This distance can be fed into ABC as a measure of the goodness-of-fit of the parameters being evaluated.
Using ABC parameters for the infectious rate of the base virus and initial immunity of the population are found. Figure 1 visualises the output from ABC: the distributions of likely parameters that best match the covid cases from data during the time period being simulated. See that the darkest orange region is considered optimal – that relatively low initial immunity, and pretty small infectious rate for the simulator matches real data. It is important to note that we do not find a single optimal point, rather we find a region of best parameters. We can see that there might well be some relationship that can be drawn to match the true data that balances infectious rate and initial immunity.
Using a single parameter tuple from the dark orange region we can re-simulate and see the full output of the calibrated model. In the animated GIF below, Figure 2, we see that the simulation initially follows close to the true data cases line. The calibrated model initially proves useful, as the predicted number of cases is close to the true number of cases. This gives us a model which predicts reality well… until, of course, the world changes.
Model Synchronisation when the World Changes
When covid mutates and a new strain is introduced our simulation needs recalibrating, or synchronising, with the real-world data. Models can fall out of calibration, slowly over-time or through substantial bifurcations in reality and in the idealised model. We find our model deviates significantly beyond timestep 60 – shown in Figure 2. With exterior subject-matter knowledge we know that this maps well to the introduction of a new strain, the delta-variant, which became prevalent at the time of the G7 summit. Hadean’s work in this space is more generally looking at the impact of the G7 summit on covid spread.
The model is therefore updated. We expect that this surge of cases is caused by an influx of a new strain in the population that coincides with the G7 summit in Cornwall. To model this, OpenABM-Covid19 allows distinct strains. We find ourselves in a similar position to which we started. The new strain must be calibrated so that it is capable of providing reasonable future insights.
Figure 3 details the experiments on one plot. The first ABC experiment discussed, for the Figure 1, uses a seeding period between the first two blue dashed lines, A-B, and with the distance metric that compares true data to simulated in the region between B and C. The second ABC experiment to parameterise a new variant uses as static parameters the values from the first ABC experiment, seeding at the start, running the model freely in the same region, then at step 58, C, introducing a new virus with variable initial immunity and viral strength to be calibrated over. The distance metric for the second experiment is how well the model matches the true data beyond the line D.
In particular, Figure 3 utilises the best output from both ABC experiments, and the orange line can be seen as the best way to match the true data using parameters in the OpenABM-Covid19 simulation. What is of note is the ability for the simulation to match the peak of the new strain influx. Most importantly, note the stark difference in our recalibrated model in Figure 3 versus the initial model previously plotted in Figure 2. Model recalibration is a necessity in maintaining predictive digital twins for policy planning.
Beyond the pandemic – real-time data assimilation for digital twins
We will end here with a quick summary of what this work with Imperial College and Oxford University has taught us, and how Hadean’s technology was crucial to its execution.
In epidemiological modelling, it was found that predictive digital twins, once calibrated, require continuous resynchronisation with real-world data in order to provide decision makers with reliable modelling. We were therefore tasked with leveraging Hadean technology to keep a complex epidemiology model calibrated in the introduction of a new strain, finding Approximate Bayesian Computation to be a suitable method for doing so, both due to its model agnosticity, and because the confidence estimates it provides in a distribution of parameters gives a deeper understanding of the complex model than other techniques. Our success in this regard has established a foundation for investigating the effect of large-scale introductions of new variants in the future.
Beyond pandemic modelling, this work has taught us a lot about the importance of model calibration to the decision support process in general. We can distil this down into two core learnings:
1. Your model is only useful when you can be confident it correctly reflects reality
2. A model which is correct at one point in time can be dangerously wrong at another without recalibration
Digital twins as found in industry and defence are also susceptible to desynchronisation and must be recalibrated to provide operational utility. Without the ability to calibrate and synchronise complex digital twins with variable real-world data in a timely and accurate manner, simulation insights are incapable of providing suitable staging for developing real-world policy or systems control. For example, the following Digital Twins would be of limited use:
– A digital twin of disease spread, where you haven’t parameterised the immunity to the virus
– A digital twin of a jet engine, where you haven’t found the correct value of the friction and wear on the bearings
– A digital twin of a supply chain, where you don’t know how the network responds to bad weather
Hadean’s cloud-enabled calibration enables decision makers to leverage dynamically provisioned computing resources in the cloud, ensuring access to the computing power required to deliver predictive simulation data that is comprehensive, accurate and timely enough to provide confidence in decision-making and guide teams through uncertainty at pace.
Aside from impacting pandemic response, examples of how Hadean technology has benefited decision makers include enabling a multinational pharmaceutical company to support decision making across its global supply chain, as well as serving as the technological backbone for ‘The Forge’, a Digital Decision Support Engine for military operations developed by Cervus. In each case, the Hadean platform has proven to be an essential component in revolutionising operational efficiency in complex and highly time-sensitive contexts.
If you’d like to know more about Hadean’s capabilities with Digital Twins, please continue reading here.